
Como referenciar este texto: ‘Do fluxograma ao código: Um recomendador inteligente de algoritmos de Machine Learning’. Rodrigo Terra. Publicado em: 26/06/2025. Link da postagem: https://www.makerzine.com.br/dados/do-fluxograma-ao-codigo-um-recomendador-inteligente-de-algoritmos-de-machine-learning/.
Escolher o algoritmo certo é uma das decisões mais desafiadoras para quem está começando a trabalhar com aprendizado de máquina. Com tantas opções disponíveis — árvores de decisão, máquinas de vetores de suporte, regressões lineares, redes neurais e muito mais — é comum se deparar com a dúvida: “Por onde começar?”
Mesmo com uma base de dados em mãos, saber qual algoritmo aplicar exige um mínimo de entendimento sobre o tipo de tarefa (classificação, regressão, agrupamento, etc.), a natureza das variáveis, o volume de dados e até a importância de determinadas características. Para quem está dando os primeiros passos, essa escolha pode ser confusa ou até paralisante.
Foi justamente para ajudar nesse processo que o time do Scikit-learn desenvolveu um fluxograma visual bastante conhecido na comunidade de ciência de dados. Ele orienta, passo a passo, o usuário até uma sugestão de algoritmo com base em perguntas simples como: “Você tem mais de 50 amostras?”, “Está prevendo uma categoria ou uma quantidade?”, “Sua base é textual?” — entre outras.
Apesar de muito útil, o fluxograma é estático: ele não interage com os dados reais do usuário e exige que a pessoa navegue manualmente pelas possibilidades. Isso me levou a fazer a seguinte pergunta: e se esse fluxograma pudesse ganhar vida, interagindo com o usuário e analisando os dados automaticamente?
Inspirado no infográfico oficial da biblioteca Scikit-learn, decidi transformar o caminho decisório manual em uma ferramenta automatizada, capaz de guiar o usuário — mesmo sem experiência prévia — até a escolha do algoritmo mais adequado para seu problema de aprendizado de máquina. O resultado foi um script em Python simples, mas poderoso, que une lógica condicional, leitura de dados e interação em tempo real com quem estiver usando a ferramenta.
A Inspiração Visual
Toda boa ideia nasce de uma faísca. No meu caso, ela veio de uma imagem.
Ao explorar a documentação da biblioteca Scikit-learn — uma das mais populares para machine learning em Python — encontrei um infográfico que já tinha visto algumas vezes, mas que dessa vez me chamou atenção de outro jeito. Trata-se de um fluxograma de algoritmos, criado para ajudar desenvolvedores e cientistas de dados a tomarem decisões mais seguras na hora de escolher um modelo.
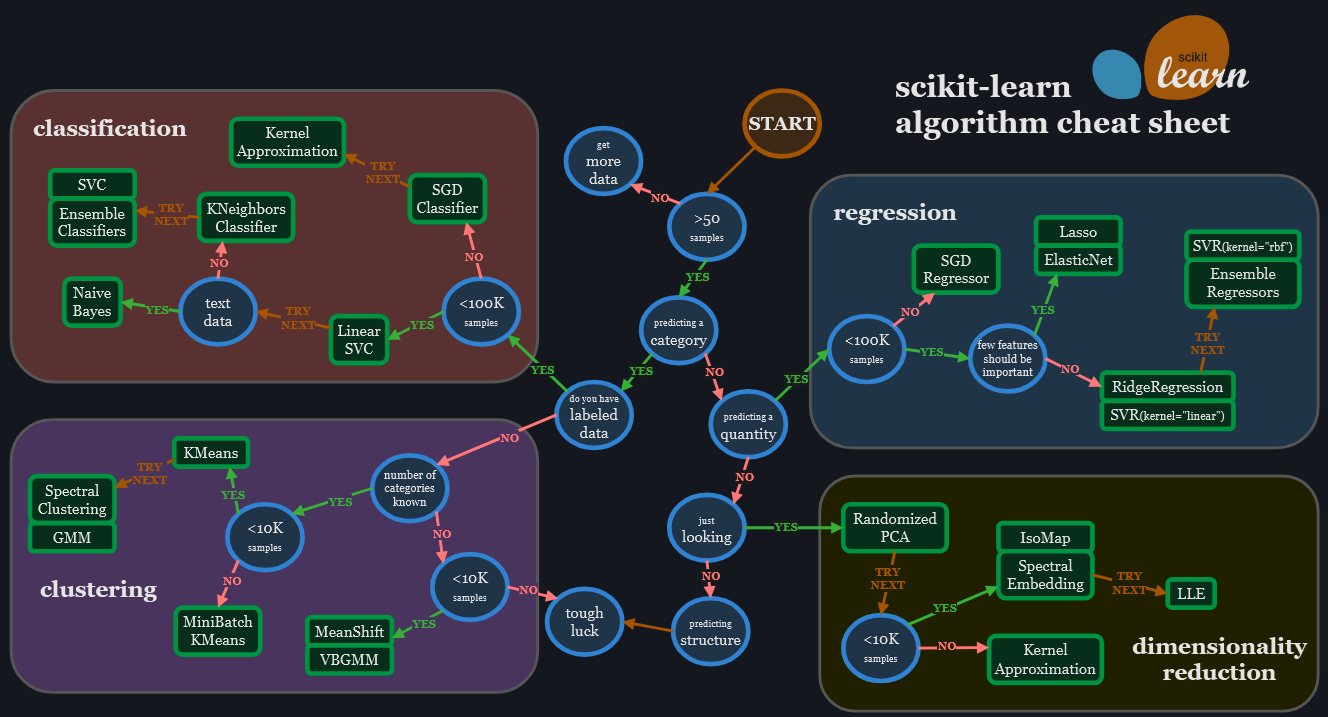
Diagrama retirado do site: https://scikit-learn.org/stable/machine_learning_map.html
O fluxograma parte de uma pergunta simples: você tem mais de 50 amostras? A partir daí, ele guia o leitor por uma sequência lógica de decisões, levando em consideração se a tarefa é supervisionada ou não, se o objetivo é classificar, prever uma quantidade, reduzir a dimensionalidade ou agrupar dados. O caminho se bifurca a cada resposta, até culminar na sugestão de um algoritmo ideal, como KMeans, RandomizedPCA, SGDClassifier ou Naive Bayes.
A beleza do fluxograma está justamente em sua simplicidade visual e organização didática. Para quem está começando, ele funciona quase como um mapa — acessível, direto e abrangente. No entanto, percebi que ele também traz uma limitação importante: por ser uma imagem estática, ele não consegue analisar automaticamente os dados do usuário, nem interagir com variáveis específicas que podem influenciar a escolha.
Foi aí que surgiu a ideia: transformar esse fluxograma em um código executável, capaz de analisar um dataset real, realizar algumas perguntas estratégicas e, com base nelas, sugerir um algoritmo apropriado. Em vez de apenas observar o diagrama e tentar se localizar, o usuário poderia conversar com o sistema — e esse sistema tomaria as decisões por ele, de forma guiada, transparente e pedagógica.
Com isso, o infográfico deixou de ser apenas uma referência visual e passou a ser a espinha dorsal de um pequeno sistema de recomendação inteligente.
O Projeto: da Análise à Recomendação
Transformar um fluxograma visual em um sistema funcional exigiu mais do que apenas seguir os passos do diagrama. Era preciso pensar em como o código poderia simular o papel do facilitador: alguém que lê os dados, entende o problema e faz perguntas relevantes para guiar a escolha do modelo.
O projeto foi implementado em Python, utilizando principalmente a biblioteca pandas para leitura e análise de dados, e blocos de lógica condicional (if-else) para replicar as decisões do fluxograma. O funcionamento é simples e interativo:
O usuário fornece uma base de dados, geralmente no formato
.csv.O sistema faz uma análise inicial, contando o número de amostras e variáveis.
Em seguida, o usuário responde a algumas perguntas estratégicas, como:
A base possui uma variável-alvo?
O objetivo é classificar categorias ou prever valores numéricos?
Você quer encontrar padrões, ou reduzir a quantidade de variáveis?
A cada resposta, o sistema segue um caminho interno que espelha as bifurcações do fluxograma original.
Ao final, um algoritmo é sugerido, compatível com o tipo de tarefa e as características do conjunto de dados.
Por exemplo: se a base tem mais de 50 amostras, a variável-alvo é categórica e os dados não são textuais, o sistema pode recomendar o uso de um LinearSVC ou KNeighborsClassifier. Já se o objetivo for reduzir a dimensionalidade de uma base com muitas variáveis, o RandomizedPCA pode ser indicado como melhor ponto de partida.
A proposta, no entanto, não é apenas técnica. Este projeto também é pedagógico. A interação com o usuário tem um papel essencial: em vez de automatizar tudo silenciosamente, o sistema explica suas escolhas, fazendo com que o processo de recomendação também seja um processo de aprendizado.
Com isso, a ferramenta se torna útil tanto para quem está começando e precisa de orientação, quanto para educadores que desejam demonstrar, de forma prática, como diferentes tarefas de aprendizado de máquina exigem abordagens distintas.
Sobre o código
O código do projeto foi escrito em Python, com foco em legibilidade e lógica progressiva. Ele utiliza a biblioteca pandas para análise inicial da base de dados e estruturas condicionais (if-else) para replicar os caminhos do fluxograma do Scikit-learn. A ideia central foi criar um sistema modular e fácil de entender, mesmo para quem está começando na programação ou no aprendizado de máquina.
As decisões foram estruturadas em blocos sequenciais que simulam perguntas feitas ao usuário, permitindo que o código se adapte ao tipo de tarefa (classificação, regressão, clustering ou redução de dimensionalidade). Tudo isso acontece em tempo real, com respostas coletadas via terminal, o que reforça o caráter interativo e pedagógico da ferramenta.
O projeto está pronto para crescer: o código já prevê pontos de expansão para inclusão de métricas, execução automática dos modelos sugeridos e integração com interfaces gráficas. Cada parte do script foi escrita com atenção à clareza, com comentários explicativos e organização lógica que facilita o aprendizado e a manutenção.
Se você acha que este conteúdo pode ser útil para alguém, compartilhe!
Ao divulgar os textos do MakerZine, você contribui para que todo o material continue acessível e gratuito para todas as pessoas.





