Conteúdos dessa postagem
O que são Redes Neurais Artificiais?
As redes neurais artificiais são uma das principais técnicas da inteligência artificial, e têm sido amplamente utilizadas em diversas áreas, desde finanças e comércio até saúde e medicina. Essas redes são especialmente úteis quando se trata de problemas complexos e não-lineares, onde as soluções baseadas em regras simples são insuficientes.
Uma das vantagens das redes neurais artificiais é a sua capacidade de aprender e se adaptar continuamente a novos dados. Por meio do processo de treinamento, a rede ajusta seus parâmetros internos para otimizar a precisão de suas previsões. Isso significa que, quanto mais dados a rede processa, mais precisa e confiável ela se torna.
Além disso, as redes neurais artificiais têm sido combinadas com outras técnicas de inteligência artificial, como algoritmos genéticos e algoritmos de enxame, para criar sistemas ainda mais poderosos e flexíveis.
Uma das áreas em que as redes neurais artificiais têm se destacado é no processamento de imagens. Por exemplo, as redes neurais podem ser treinadas para reconhecer faces humanas em imagens digitais, identificar objetos em tempo real em vídeos ou melhorar a qualidade de imagens de baixa resolução. Isso é particularmente útil em aplicações de segurança, onde a identificação precisa de pessoas e objetos é crucial.
Outra aplicação importante das redes neurais artificiais é no campo da medicina. As redes podem ser usadas para prever o risco de certas doenças em pacientes com base em seus dados médicos, ou para analisar imagens médicas para detectar doenças precocemente.
Matematicamente falando ...
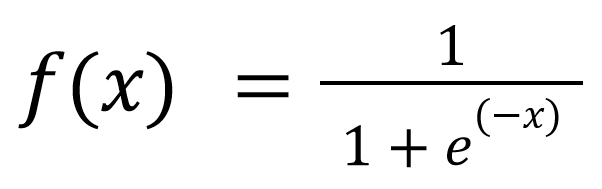
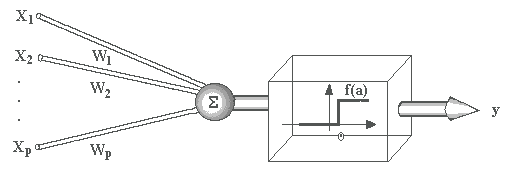
Durante o treinamento de uma RNA, os pesos das conexões são ajustados iterativamente para minimizar a diferença entre as saídas da rede e as saídas desejadas. Isso é feito usando um algoritmo de otimização, como o gradiente descendente, que calcula as derivadas parciais da função de perda em relação aos pesos da rede e ajusta os pesos para minimizar a função de perda.
A complexidade matemática de uma RNA aumenta com o número de camadas e neurônios na rede. Redes mais profundas e complexas podem aprender a representar relações mais abstratas e complexas entre as entradas e as saídas desejadas, mas também podem ser mais difíceis de treinar e ajustar corretamente.
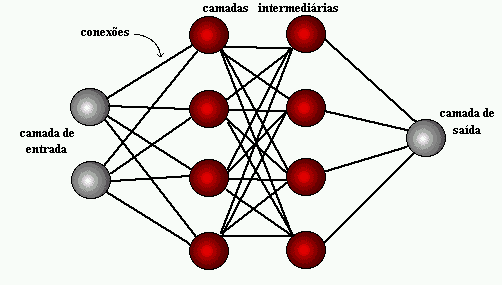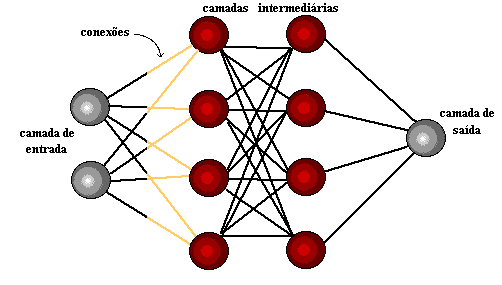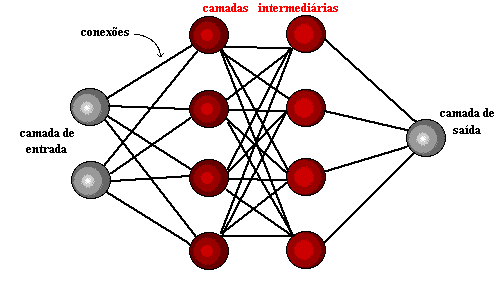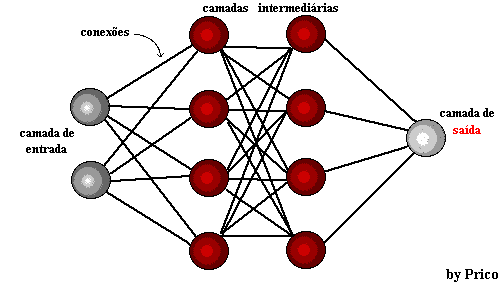
Como foram desenvolvidas?
As redes neurais artificiais têm suas raízes na década de 1940, quando o matemático Warren McCulloch e o neurofisiologista Walter Pitts propuseram um modelo matemático para o funcionamento dos neurônios no cérebro. Esse modelo, conhecido como neurônio artificial, serviu de base para o desenvolvimento das redes neurais artificiais.
Na década de 1950 e 1960, vários pesquisadores, incluindo Frank Rosenblatt, desenvolveram as primeiras redes neurais artificiais para reconhecimento de padrões e aprendizagem automática. Essas redes eram baseadas em neurônios artificiais interconectados, que podiam ser treinados para reconhecer padrões em imagens ou sinais.
No entanto, na década de 1970, as redes neurais artificiais caíram em desuso, devido à falta de técnicas eficientes de treinamento e à limitação computacional da época.
Foi somente na década de 1980, com o desenvolvimento de novas técnicas de treinamento, que as redes neurais artificiais voltaram a ganhar destaque. Uma dessas técnicas foi a retropropagação de erros, que permitiu treinar redes neurais com várias camadas (conhecidas como redes neurais profundas) de forma eficiente.
Desde então, as redes neurais artificiais evoluíram significativamente, tanto em termos de estrutura quanto em técnicas de treinamento e aplicação. A explosão de dados e o aumento da capacidade computacional permitiram o desenvolvimento de redes neurais cada vez mais poderosas e sofisticadas, capazes de lidar com problemas cada vez mais complexos e variados.
Hoje em dia, as redes neurais artificiais são amplamente utilizadas em diversas áreas, como processamento de imagens e áudio, reconhecimento de voz, análise de dados, previsão de eventos e muitas outras aplicações.
Um exemplo em Python
import tensorflow as tf
from tensorflow import keras
(x_train, y_train), (x_test, y_test) = keras.datasets.mnist.load_data()
x_train = x_train.astype('float32') / 255.0
x_test = x_test.astype('float32') / 255.0
y_train = keras.utils.to_categorical(y_train)
y_test = keras.utils.to_categorical(y_test)
model = keras.Sequential([
keras.layers.Flatten(input_shape=(28, 28)),
keras.layers.Dense(64, activation='relu'),
keras.layers.Dense(64, activation='relu'),
keras.layers.Dense(10, activation='softmax')
])
model.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy'])
model.fit(x_train, y_train, epochs=10, batch_size=32, validation_split=0.2)
Este código treinará a rede neural por 10 ciclos (ou seja, passagens completas pelo conjunto de treinamento), com um tamanho de lote de 32 exemplos por vez, e monitorará a acurácia de validação durante o treinamento.
Depois de treinar a rede neural, podemos avaliá-la nos dados de teste:
test_loss, test_acc = model.evaluate(x_test, y_test)
print('Test accuracy:', test_acc)